What convinces Q&A models?
Often when we want to answer a question, we aren’t just interested in the answer, but also in why we think that answer is true. In case we’re wrong, we’re also interested in why other answers could be true. In short, we’re interested in the evidence for any answer.
Finding evidence can be hard work. For instance, finding evidence can require searching through large amounts of text. We found a way to find evidence automatically: probing machine-learned models.
Example
As an example, let’s take answering multiple-choice questions about a passage. Here’s one passage/question (no need to read it all — the most relevant parts are in bold):
Passage: Americans often say that there are only two things a person can be sure of: death and taxes. Many people feel that the United States has the worst taxes in the world. Taxes are the money that people pay to support their government. There are generally 3 levels of government in the U.S.: federal, state, and city; therefore, there are 3 types of taxes. Salaried people who can earn more than four to five thousand dollars per year must pay a certain part. It depends on their salaries. The federal government has a two-level income tax: that is, 15 or 28%. $17,850 is the cut off. The tax rate is 15% below $17,850 and 28% above. The second tax is for the state government: New York, California, or any of the other 48 states. Some states have an income tax similar to that of the federal government. Of course, the percentage for the state tax is lower. Other states have a sales tax, which is a percentage charged to any item which people buy in the state. Some states use income tax and sales tax to raise their revenues (= annual income). The third tax is for the city. This tax comes in two forms: property tax (people who own a home have to pay taxes on it) and excise tax, which is collected on vehicles in a city. The cities use this money for education, police, public works, etc. Since Americans pay such high taxes, they often feel that they are working one day each week just to pay their taxes. People always complain about taxes. They often say that the government misuses their tax dollars. They all believe that taxes are too high in this country.
Question: In the U.S., taxes provide revenue for the…
A. federal government
B. state government
C. city government
D. 3 levels of government
To find evidence for each answer choice A–D, we could ask someone about each passage sentence: “Which answer does the sentence support?” But asking somebody about each sentence is time-consuming (and boring). Instead, can we replace the person with a Q&A model?
First, we train a Q&A “Judge Model” (BERT) which we’ll use to judge the answer given different sentences. Then, we’ll have an “Evidence Agent” find the passage sentence that most convinces the Judge Model of an answer. The Evidence Agent can be another machine-learned model or a simple algorithm (“try out every sentence and choose one that convinces the Judge”). Here’s what happens:
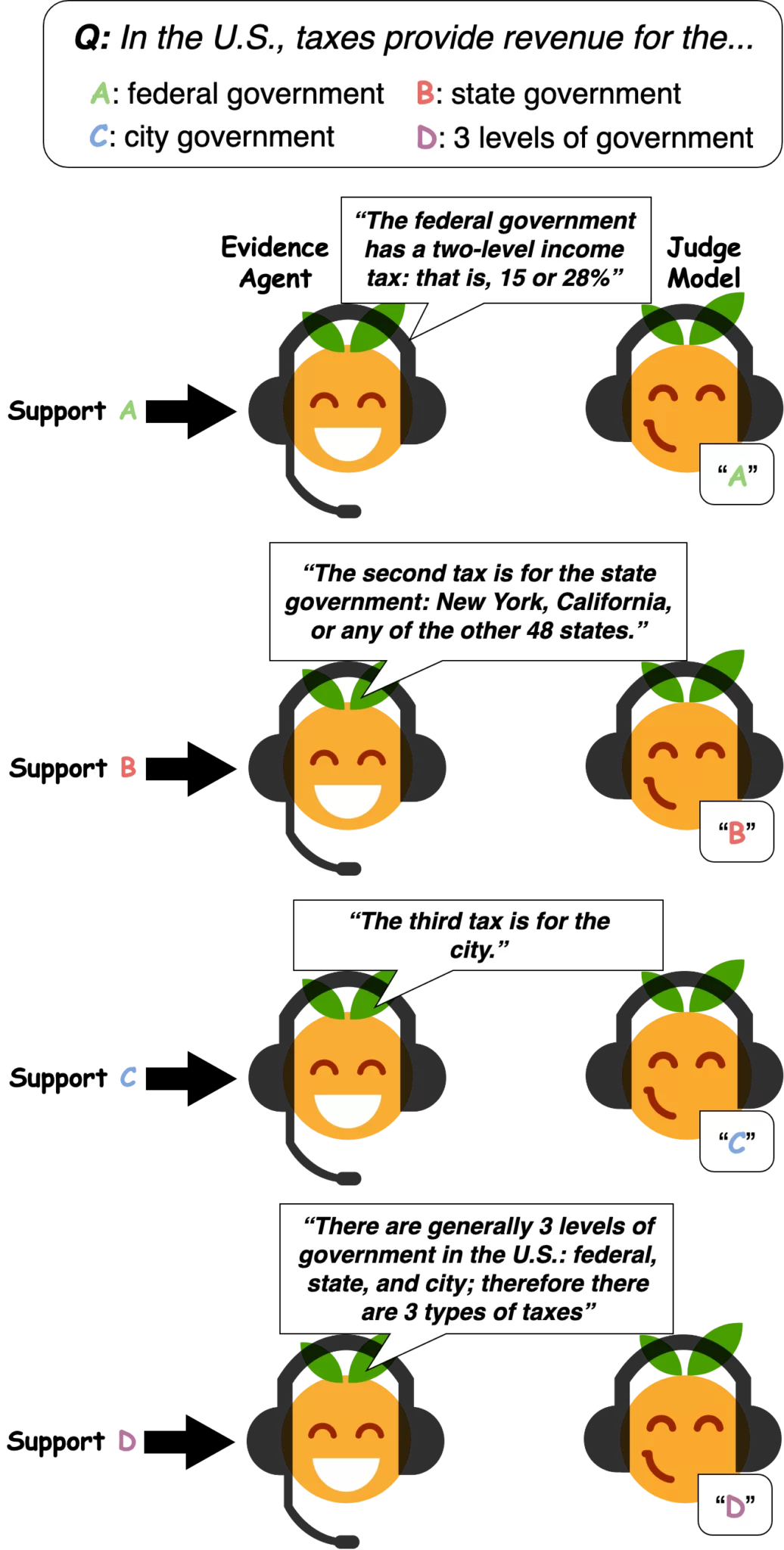
It turns out that the Judge Model is convinced by statements that do in fact support the associated answer. When we gave the agent-chosen evidence to people, they tended to agree with the Judge Model’s answer:

Agent-chosen evidence is useful to Q&A models too. Q&A models are better at answering questions based on agent-chosen evidence rather than the whole passage. For example, Q&A models can generalize to longer passages than seen during training when using agent-chosen evidence. Q&A models can also better answer high-school level questions even if we have only trained the model to answer middle-school level questions. In short, model-chosen evidence helps models answer harder questions.
Why Machine Learning Researchers Should Care
Machine-learned models are well-known to behave differently from people. Neural networks have adversarial examples and exploit dataset biases. The models that we used don’t understand language well; our best model only gets a C+ on grade-level English exams (69% accuracy). That’s why it’s surprising that models still use similar evidence as people do. What’s more: as models get better, similarity to people grows:
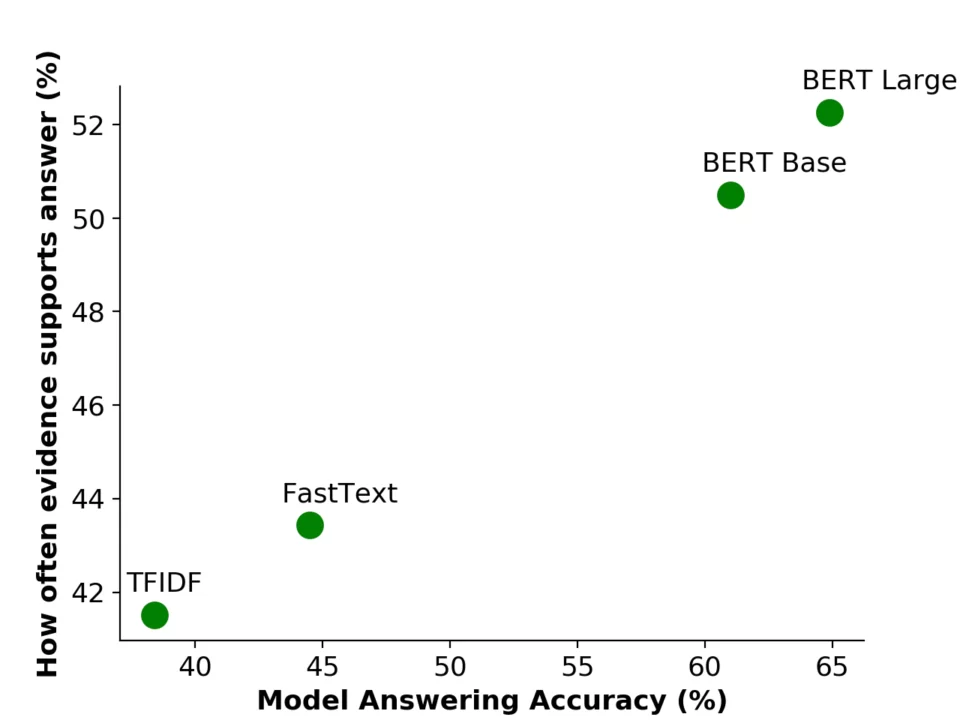
Why do we care if models and people make judgments in similar ways? We care since that would let us replace people’s judgments for a model’s judgment in situations that we care about. For example, it would be easier for me to improve this blog post if I knew how much readers would like each draft of the post. In machine learning, we’d often like to train models based on feedback from people (i.e., how much they enjoy talking with a chatbot or how convincing a machine-generated argument is). Having models judge instead of people can save us a lot of time.
From a scientific standpoint, we have a new way to probe how people think: probing machine-learned models.
Read our EMNLP paper here, or train your own Evidence Agents using our code.