Inverse Scaling Prize

Few-shot Adaptation Works with UnpredicTable Data
August 1, 2022
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
November 8, 2022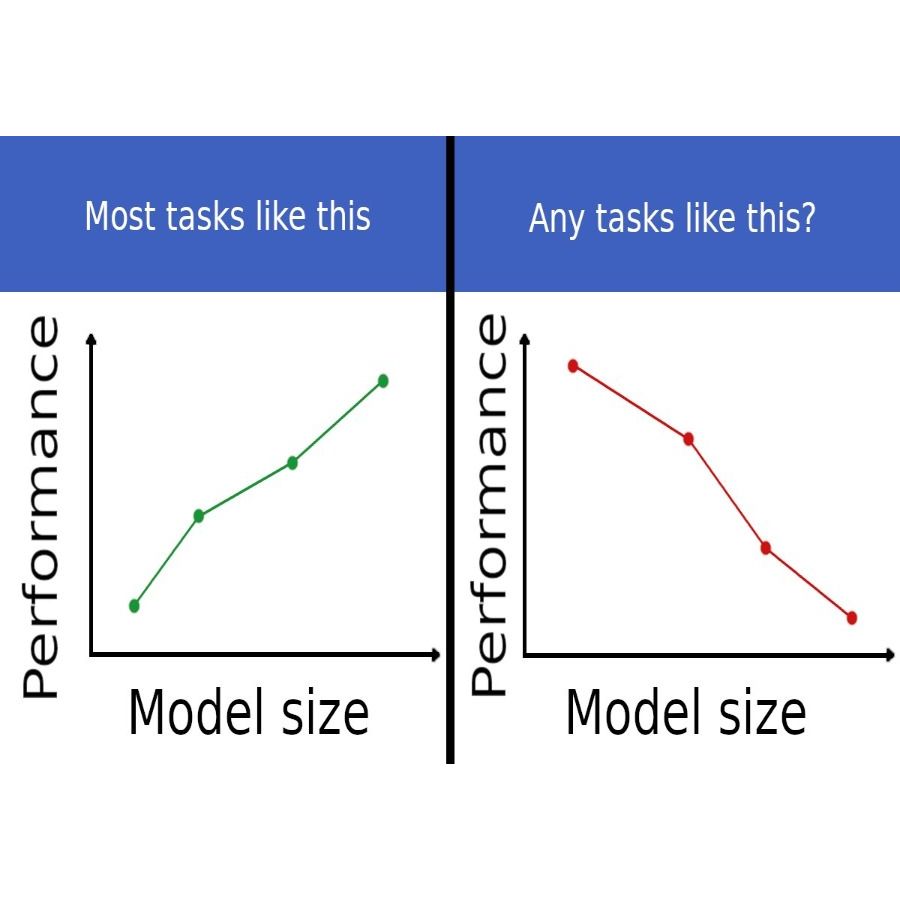
We’re announcing the ISP: a $100k grand prize + $150k in additional prizes for finding an important task where larger language models do *worse*.
Publication:
Collaborators: Ian McKenzie, Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman, Ethan Perez